Planning analytics modeling - Allocations

Another one of the ‘what do a I think about when doing X in PA’ posts (see the previous one on General Ledger), this time covering everyone’s favourite topic: Allocations!
I rarely encounter a planning system without an allocation component in it, it’s such a fundamental step to understanding profitability or ’true costs including overheads’ for a product / cost centre / project / process or any other object.
A few design considerations I usually think of when discussing allocations:
- What is the ‘grain’ / ‘dimensionality’ of the allocation? Are we allocating cost centre expenses to a product or, say, freight costs across different products? What are the source / target dimensions?
- Are we talking about multi step allocations (i.e. Cost Centre A allocates to B and then B transfers the full cost to C)? Ideally you don’t want multiple steps, but they can be required, especially anywhere around manufacturing
- Who is initiating the allocation process (sender, receiver, schedule?) and whether there’s a workflow required to notify / approve by receivers? The more complicated approval process is, the harder you need to think about overrides you need to build-in to circumvent it (think people being on holiday / in a meeting when change needs to be made, last minute board meeting adjustments, etc). It’s worth having a separate ‘sandpit’ scenario if the approval process is fairly stringent to allow for quicker modeling. Notification + tracking of allocations is my default suggest and I push-back on building an approval process, as it almost always gets removed or disabled later.
Here’s how I see an allocation model blueprint:
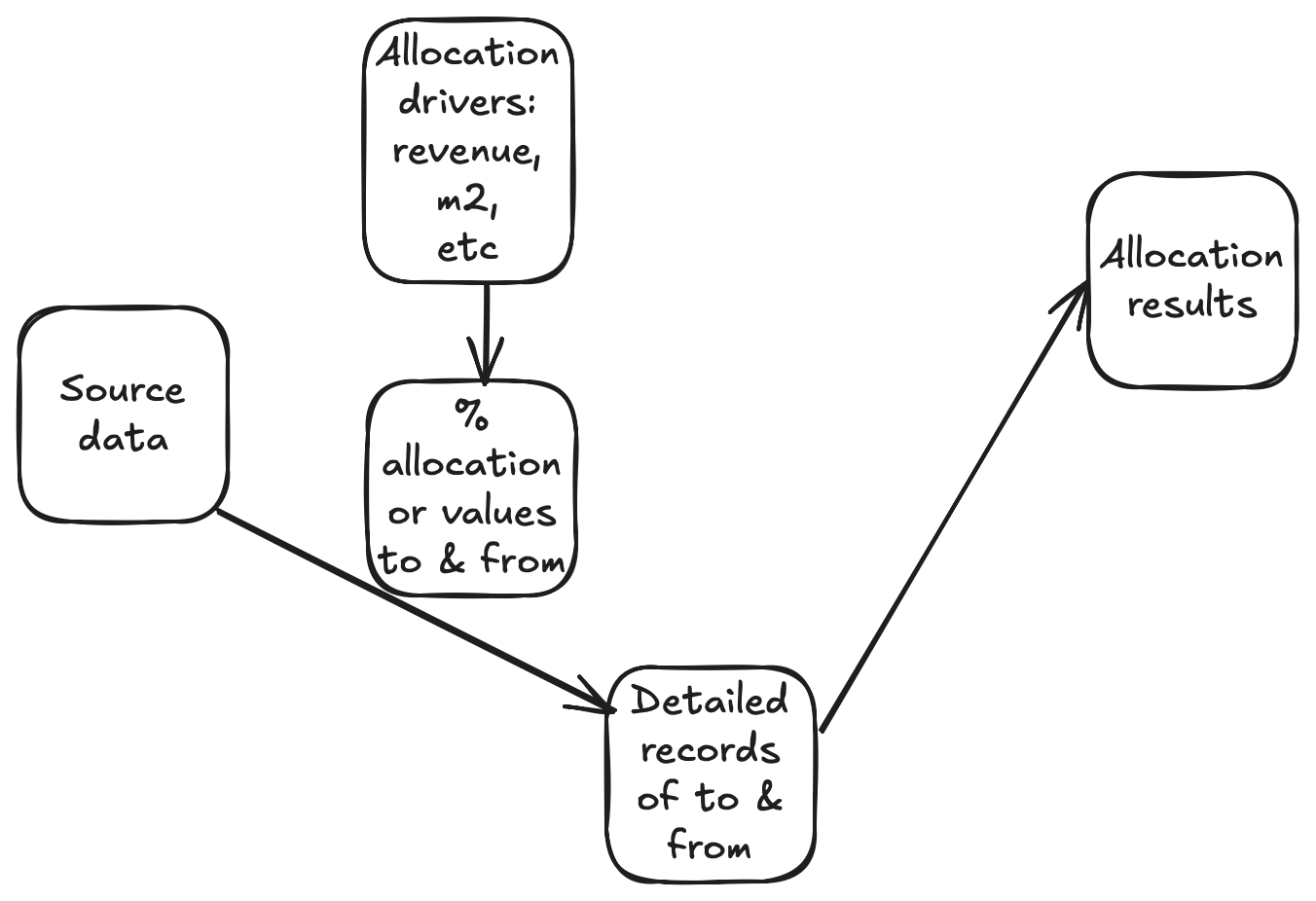
- No rule based allocations :) Everyone starts with allocating via rules (rules are powerfull and traceable, yay, processes are complex, boo), but it’s never going to be fast
- Allocation is based on the input of % of from / to – even if it’s driver based (for example, rent is allocated proportionally to area occupied, or based on, say, revenue). I always start with building with % input and upload and any driver based allocation is added on top by prepopulating the %s
- Aim to create a full record of to and from allocation details. It’s a lot of data, but totally invaluable for reconciling the results and building trust in the system. So, for example, if we’re doing a cost centre to cost centre there would be a cube with cost centre from, account from, cost centre to, account to breakdown. Allocation step is another dimension in the multi-step allocation scenario. No rules in such cubes.
- It’s worth to discuss the
threshold of significancewith the end users and build some logic to stop allocating below this threshold. Having 0.0000001$ allocations only slows things down and brings no real value. - I’m trying to make allocation process to run as fast as possible (performance is my quirk, maybe because it’s the easiest to measure), which is mainly by limiting the amount of source data read and ’tighten’ the allocation loops (by pre-populating ‘possible’ intersection subsets), all the tips from the performance post apply. Running a process for allocating each source ‘record’ is an anti-pattern I unfortunately see way too often, the overheads of starting a process adds up fast.