Using AWS Athena for TM1 transaction log analysis

We all love tm1s.log files, our lifeline and an invaluable tool in the ‘why the number is X’ scenarios. They tend to get quite big though and you usually do some sort of ‘zip’em / move’em / delete’em after Y days’ automation. In this post, I’ll look into adding ‘push’em to the cloud to query’ step :)
How to analyse log files
Overall there 3 common ways of ‘querying’ the log files:
- Built-in Architect log query tool. Does the job and is the only way to search transactions before SaveData timestamps the tm1s.log file, but I have the following gripes with it:
- It’s slow, I find it way slower than scanning file with grep or PowerShell
- it’s running sequentially through log files instead of reading them in parallel. Guess it’s more of the ‘slow’ argument
- Only searches the logs present in the server log folder and uncompressed. Usually, I cannot store a year or two worth of logs in the same location.
- I don’t like having a running thread in Architect while it searches through logs, I’m always afraid of locking something. Not sure what happens when multiple search at the same time :)
- I’m a SQL guy at heart, so I miss wildcards in searches
- Transaction logs are just text files, after all, so grep and PowerShell searching, Notepad++ Find in Files, all of this works fine and dandy. File searches carry over the same challenges with speed & parallelism, not working over compressed files and lack of query language. But it is by far the most common way
- Loading committed log files to a database. I rarely see this, but this is the way I like most so far as it gives you good performance and SQL interface. The main downside is that you need to create an ETL pipeline for logs and implement some sort of data retention policy. And you need a database to host this, which might be no small feat as tm1 transaction logs can get quite big.
So while I was doing the unzip / search routine the other day and thought that there should be another way.
AWS Athena
Enter Amazon Athena : a serverless query engine on Amazon Web Services. Athena (a Presto cluster in the background) provides you with a SQL interface to files stored in Amazon S3 buckets that works over compressed files as well.
So what you do is:
- you create a bucket in S3 to store your log files
- ideally create folders by month or year so that we can specify them as partitions to avoid scanning extra data, see below for sample table creation (substitute the bucket name appropriately)
- upload your compressed tm1 log files to the folders (either manually through a web interface or using AWS CLI)
- Create the Athena table (see code below). You should partition your Hive table by month or year to decrease the amount of data scanned.
- Start querying your transactions :)
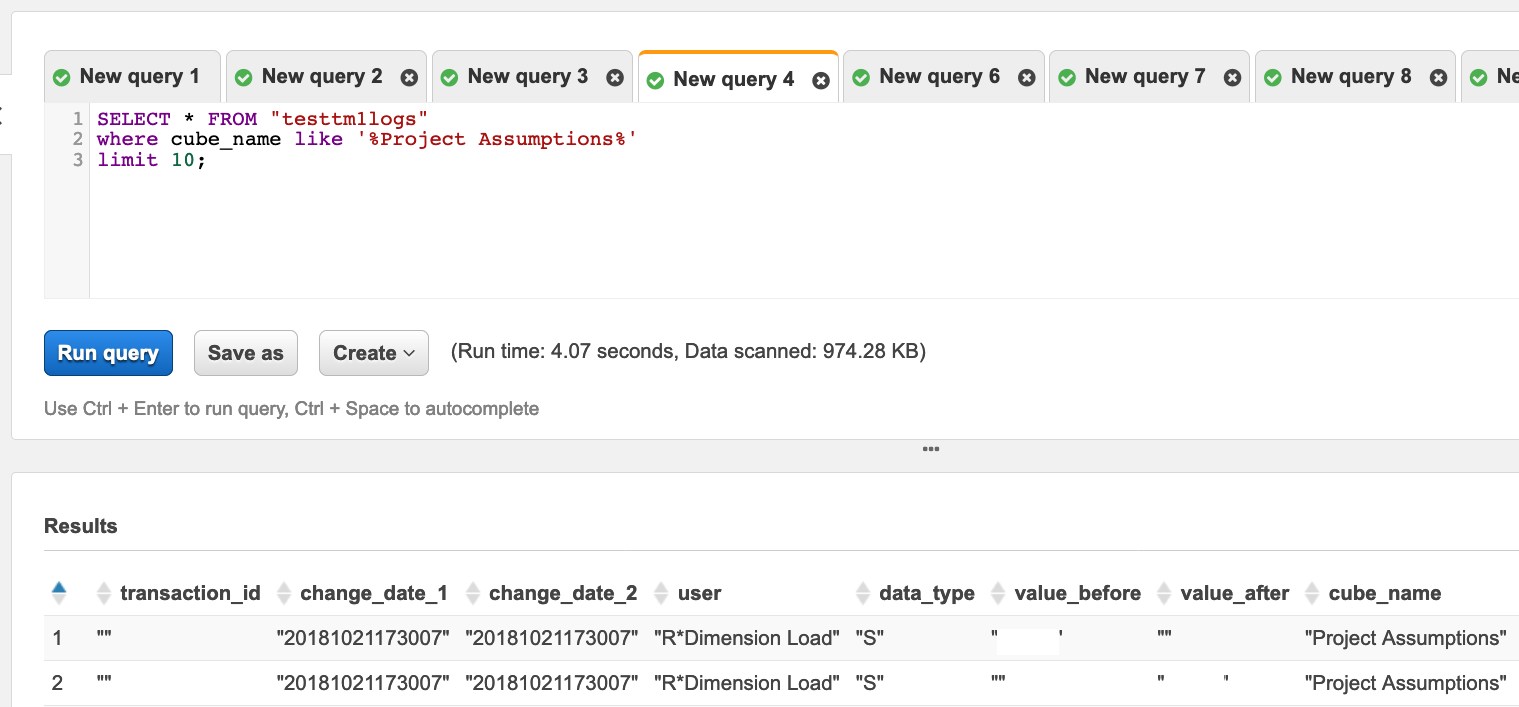
How much will this cost
Let’s run some numbers.
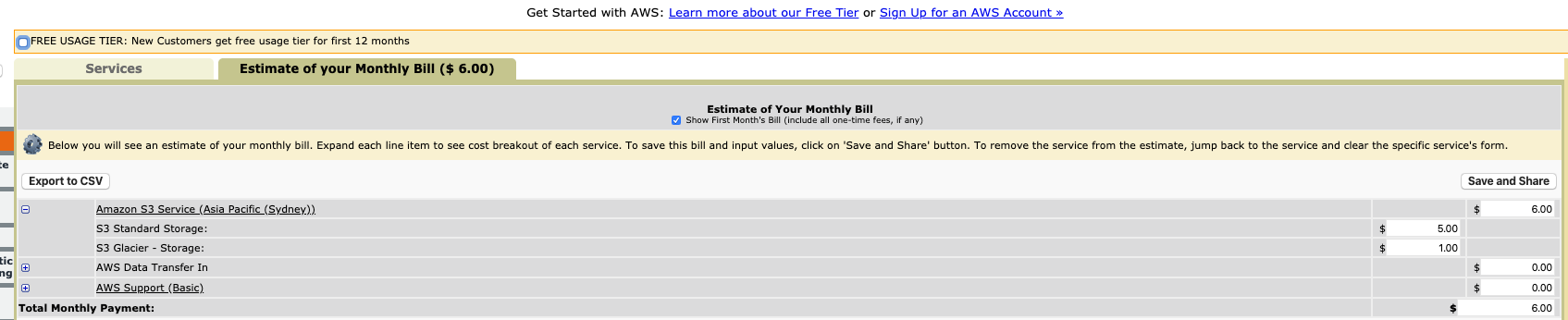
Say we will be uploading 500Mb compressed log files daily (that’s around 15b uncompressed transaction log, a pretty decently loaded TM1 system) and would want to store a year worth of log files that you will query and move them to Glacier after that (a lot cheaper, you wouldn’t be able to query them unless you explicitly ‘unfreeze’ them):
- 500MB * 365 = 182 Gb, let’s round it up to 200
- 200 GB in S3 standard will cost 5$ a month
- 200 GB of Glacier (for previous year archive) will cost 1$ a month
So overall storage cost would be 6$ a month
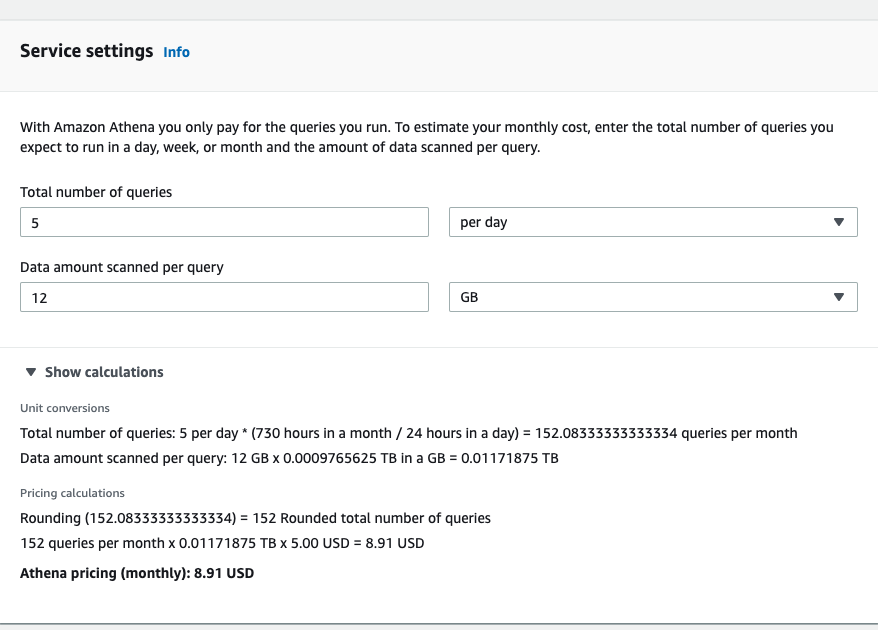
Athena queries cost 5$ per Tb data scanned, so if you run 5 queries overall all of last month’s files (12 Gb per query), it’d be ~9 USD per month.
With 500Mb you shouldn’t be paying for data in / out, but let’s put aside another couple bucks for it.
Overall, for ~25$ per month, you’d get 2 years worth of 15 Gb daily tm1s logs stored safely with an SQL interface on top.
Some extra benefits of this approach:
- S3 buckets allow you to configure lifecycle policies, moving older files to cheaper storage and removing them after a while. You can put older logs to Glacier safely as well as Athena ignores Glacier files while querying.
- S3 bucket encryption throughout, this information can be quite sensitive.
- Athena provides ODBC / JDBC drivers, so you can point your favourite BI tool and have a nifty dashboard :)
I would do something similar in BigQuery if you’re on Google Computing Cloud and in Azure Data Lake.
Sample table create for tm1s log files:
CREATE EXTERNAL TABLE `tm1s_logs`(
`transaction_id` string,
`change_date_1` string,
`change_date_2` string,
`client` string,
`data_type` string,
`value_before` string,
`value_after` string,
`cube_name` string,
`dim1_element` string,
`dim2_element` string,
`dim3_element` string,
`dim4_element` string,
`dim5_element` string,
`dim6_element` string,
`dim7_element` string,
`dim8_element` string,
`dim9_element` string,
`dim10_element` string,
`dim11_element` string,
`dim12_element` string,
`dim13_element` string,
`dim14_element` string,
`dim15_element` string)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
WITH SERDEPROPERTIES (
'separatorChar' = ',',
'quoteChar' = '"',
'escapeChar' = '\\'
)
STORED AS TEXTFILE
LOCATION
's3://yourbucketnamehere/folder/'
TBLPROPERTIES (
'has_encrypted_data'='false',
'transient_lastDdlTime'='1571790782')